728x90
반응형
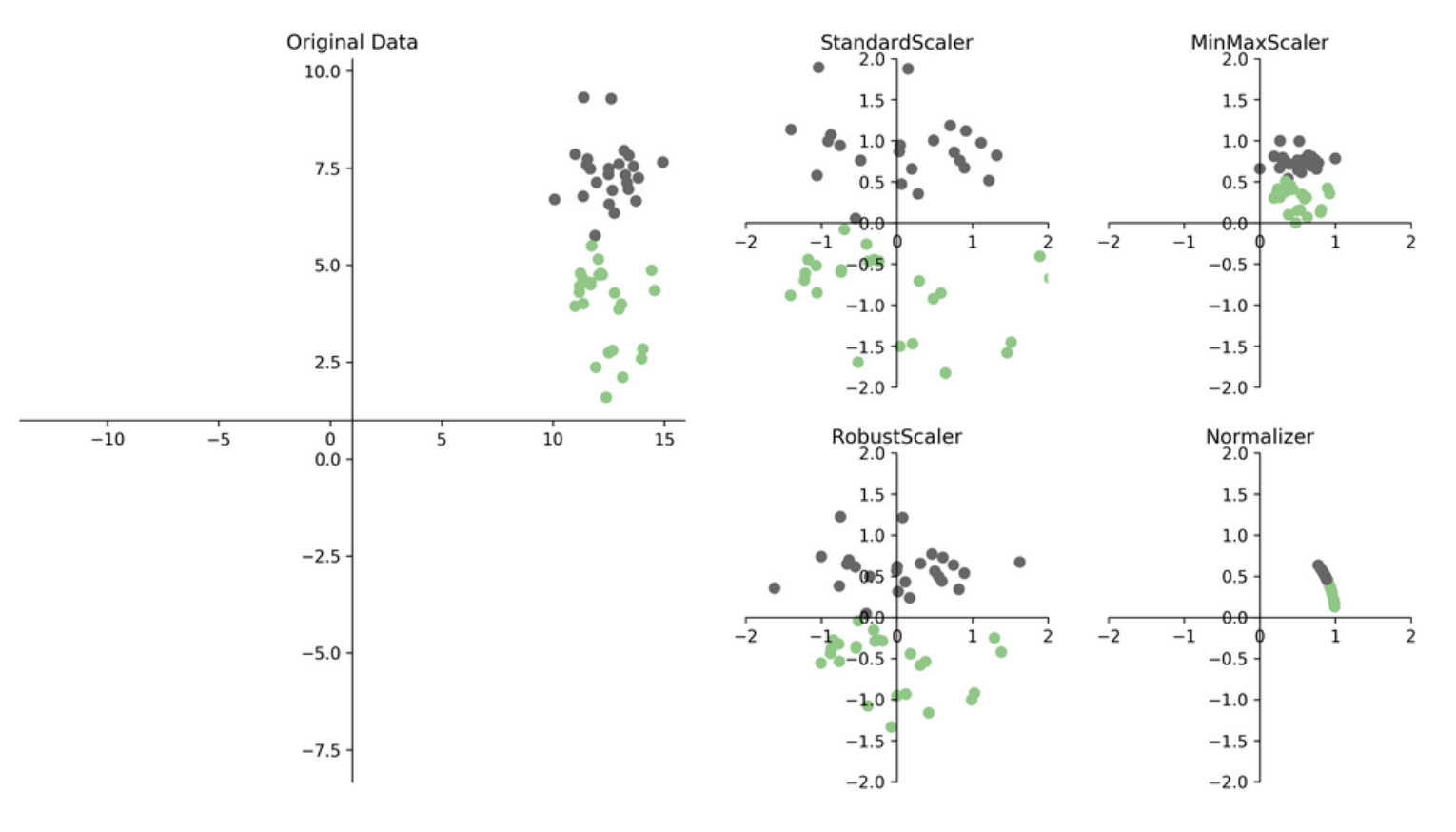
| Standard Scaler |
 |
정규 분포 형태를 따른다. 각 열의 feature 값의 평균을 0으로 잡고, 표준 편차를 1로 간주하여정규화 하는 방법 각 데이터가 평균에서 얼마간의 표준편차 만큼 떨어져 있는지를 기준으로 삼는다. 데이터의 최대치와 최고치를 모를때 사용되며 이상치에 영향을 받는다. 데이터 특징을 모르는 경우 선택 할 수 있는 가장 무난한 종류의 정규화중 하나이다. |
| Normalizer | 각 변 수의 값이 원점으로부터 1만큼 떨어진 범위로 변환한다. (=벡터의 유클리드 길이가 1이 되도록 조정한다) 빠르게 학습할 수 있고 과대적합 확률을 낮출 수 있다. 벨터의 길이가 아니라 데이터의 방향이 중요한 경우 자주 사용한다. |
|
| MinMax Scaler |
 |
각 feature의 최소값과 최대값을 기준으로 0 ~ 1 구간 내 균등하게 배정하는 정규화 방법으로 각 변수가 정규 분포가 아니거나 표준편차가 적을 때 효과적이다. 이상치에 민감하다는 단점이 있다 (min-max는데이터의 분포를 조정하지 않는다) |
| Robust Scaler |
 |
평균과 분산 대신, 중앙값과 사분위수를 사용한다는 점을 제외하면 standard scaler와 유사하게 작동한다. Q2에 대 해당 하는 데이터를 0으로 잡고 Q1, Q3사분위와의 IQR 차이만큼을 기준으로 정규화를 진행하는 방법 해당 정규화방법은 이상치에 강한 특징을 보이기에 RobustScaler라는 이름이 붙여졌으며 이상치가 많은 데이터를 다루는 경우 유용한 정규화 방법이 될 수 있다. |
Standard scaler는 이상치가 없거나 이상치 영향이 크지 않는 데이터에 사용하는 기법이고
Robust scaler는 이상치가 있는 데이터에서 이상치 영향을 최소화 하면서 스케일링 하는 기법이다.
그러나
실제 사용시 이상치에 강한 RobustScaler가 오히려 성능이 안나오는 경우도 있다.
그러니 여러 스테일러를 사용하며서 테스트를 권한다.
from sklearn.preprocessing import StandardScaler
scaler_std=StandardScaler()
X_train_scaler_std=scaler_std.fit_transform(X_train)
X_test_scaler_std=scaler_std.transform(X_test)
model_lin_reg_scaler_std=LinearRegression()
model_lin_reg_scaler_std.fit(X_train_scaler_std,y_train)
model_lin_reg_scaler_std.score(X_test_scaler_std,y_test)from sklearn.preprocessing import Normalizer
nor = Normalizer()
nor_data = nor.fit_transform(data)from sklearn.preprocessing import MinMaxScaler
scaler_minmax=MinMaxScaler()
X_train_scaler_minmax=scaler_minmax.fit_transform(X_train)
X_test_scaler_minmax=scaler_minmax.transform(X_test)
model_lin_reg_scaler_minmax=LinearRegression()
model_lin_reg_scaler_minmax.fit(X_train_scaler_minmax,y_train)
model_lin_reg_scaler_minmax.score(X_test_scaler_minmax, y_test)from sklearn.preprocessing import RobustScaler
scaler_robus=RobustScaler()
X_train_scaler_robus=scaler_robus.fit_transform(X_train)
X_test_scaler_robus=scaler_robus.transform(X_test)
model_lin_reg_scaler_robus=LinearRegression()
model_lin_reg_scaler_robus.fit(X_train_scaler_robus,y_train)
model_lin_reg_scaler_robus.score(X_test_scaler_robus,y_test)
728x90
반응형
'Data Science > Machine Running' 카테고리의 다른 글
| [ML] Cross Entropy (1) | 2023.12.18 |
|---|---|
| [ML] Model evaluation metrics (0) | 2023.07.19 |
| [ML] OrdinalEncoder, LabelEncoder,OneHotEncoder의 차이 (1) | 2023.06.24 |